Mastering Domain-Specific Language Output: Getting an LLM to Perform Reliably without Fine-tuning
See how real-world user insights drove the latest evolution of Faros AI’s Chat-Based Query Helper—now delivering responses 5x more accurate and impactful than leading models.

Earlier this year, we released Query Helper, an AI tool that helps our customers generate query statements based on a natural language question. Since launching to Faros AI customers, we've closely monitored its performance and diligently worked on enhancements. We have upgraded our models and expanded our examples to cover edge cases. We have also seen that customers want to use Query Helper in ways we did not anticipate. In this post, we'll explore our observations from customer interactions and discuss the improvements we're implementing in the upcoming V2 release to make Query Helper even more powerful.
But before we dig into the technical details — what is Query Helper?
Any engineering manager can attest that obtaining accurate, timely information about team performance, project progress, and overall organizational health is incredibly challenging. It typically involves sifting through multiple databases, interpreting complex metrics, and piecing together information from disparate sources.
Faros AI addresses this complexity by consolidating all data into a single standardized schema. However, there remains a learning curve for users to interact with our schema when their questions aren't addressed by our out-of-the-box reports. Query Helper V1 sought to simplify this process by providing customers with step-by-step instructions to obtain the information they needed.
General release and monitoring user behavior and challenges
Earlier this year, we released Query Helper to all our customers. This broad deployment enabled us to collect valuable data on usage patterns and response quality across a diverse user base. By closely monitoring these metrics, we ensure that Query Helper meets our users' needs and identify areas for improvement.
One of the most exciting outcomes of the general release has been seeing how users interact with Query Helper. It is always nice when people use what you build and we're thrilled to report that the feature has been well-received and widely used by our customers. However, we've also observed some interesting and unexpected patterns. With Query Helper’s interface being a text box where you can type whatever you want, users have been asking a much broader range of questions than we initially anticipated. This has presented some challenges.
Users had questions about how the raw data was transformed to get into the schema. They wanted help formulating complex custom expressions to get a particular metric of interest. They had general questions about Faros AI or engineering best practices. However, our single purpose Query Helper tool was only designed to provide instructions for querying the database. It provided good answers for how to build a step-by-step query in our UI but did not provide the most helpful responses to other types of questions.

Additionally, while analyzing responses to questions on building queries, we found that not all answers provided by the Large Language Model (LLM) were practically applicable. Validating these responses based solely on free-text instructions proved to be very complex. We implemented checks to confirm that all tables and fields referenced by the LLM existed in our schema. However, ensuring the accuracy of explanations on how to use these tables and fields was challenging, leaving room for potential errors that are difficult to detect. This raises the question: Is there a better way to ensure the queries generated would actually function correctly?
A rigidly structured response format allows for more thorough validation but is more difficult to generate correctly with an LLM. When we began developing Query Helper a year ago, we envisioned a tool capable of directly creating queries in our UI. However, initial tests showed this was beyond the scope of the available LLMs at that time. Over the past year however, LLMs have made significant advancements, and fine-tuning them has become easier. Is it time to revisit our original vision? If we're developing a tool to automatically create queries (as opposed to just describing how to do it), how will we address the variety of other questions customers want to ask? Furthermore, where should general question-answering be integrated within our interface?
Keep the interface simple, make the backend flexible
To address the challenge of integrating advanced query generation into our product with both flexibility and precision, we adopted a multi-pronged approach. We kept our simple text box interface (though we added a bit more guidance about what kind of questions the Query Helper can answer). The back end product evolved quite a bit. Our strategy involves utilizing an intent classifier to accurately identify the type of user query and direct it to the most suitable handling mechanism.

Before attempting to answer a user's question, we use an LLM classifier to determine what the user seeks. This classifier categorizes user queries into predefined groups: "greeting," "complaint," "outside the scope," "reports data definition," "custom expression," "text to query," "platform docs," "common knowledge," and "unclear." By tagging the intent, we ensure that each inquiry receives a response tailored to its specific context, helping to avoid odd behavior—like the LLM attempting to explain how to answer the question "hello" using our data schema.
Beyond intent classification, we incorporated tools that interact with specialized knowledge bases. These tools are essential for handling queries requiring detailed information, such as custom expressions, data definitions, and platform documentation. By leveraging these targeted resources, users receive precise and informative responses, enhancing their overall experience and understanding of the platform.
Lastly, a critical component of our approach is the capability for complete query generation. This involves translating user intentions into actionable queries within the query language used by Faros AI. With the advancements in LLMs, we are now poised to revisit our original vision, aiming to provide dynamic and accurate query completion directly within our interface.
By harnessing these three facets—intent classification, specialized knowledge access, and query generation—we aim to create a robust and responsive Query Helper that meets the diverse needs of our users while enhancing our platform's functionality. While the intent classification and knowledge base retrieval and summarization leverage standard procedures for developing LLM-based products, the query generation presents a unique challenge. Generating a working query requires more than simply instructing the model on the desired task and adding relevant context to the prompt; it involves deeper understanding and interaction with the data schema to ensure accuracy and functionality.
To tune or not to tune? And what LLM do we need to make this work?
A core question we faced was whether to fine-tune a relatively smaller LLM or use the most advanced off-the-shelf LLM available in our toolbox. One complication we faced in making this decision is that FarosAI does not expose SQL to our customers, we instead use the MBQL DSL (Metabase-Query-Language Domain-Specific Language) integrated into our UI to enable no code question answering. State-of-the-art SQL generation with LLMs is not yet perfected (Mao et al), and asking an LLM to generate a relatively niche DSL is a significantly harder task than that. We briefly contemplated switching to SQL generation due to its recent advancements, but we quickly dismissed the idea. Our commitment to database flexibility—demonstrated by our recent migration to DuckDB—meant that introducing SQL in our user interface was not feasible. This led us to consider how to make an LLM reliably produce output in MBQL. Fine-tuning appeared to be the key solution.
Our initial experiments with a fine-tuned model yielded promising results. However, surprisingly, we found that a more powerful off-the-shelf LLM performed remarkably well in this task, even without fine-tuning. Given the relatively low traffic volume for these requests, we began to consider whether an off-the-shelf model could suffice. Although it might be slower, the trade-off seemed worthwhile when weighed against the costs and maintenance challenges of deploying our own model. Maintaining a custom model can be extraordinarily expensive, not to mention the resources needed to manage continual updates and improvements.
Another factor influencing our decision was the nature of our B2B (Business-to-Business) model. Different customers have specific usage patterns with our schema, posing a unique challenge. Fine-tuning a model on such diverse data may not provide a solution flexible enough to accommodate these variations based solely on examples. A more generalized approach, utilizing a powerful off-the-shelf model, could potentially adapt better to these customer-specific nuances.
Thus, while fine-tuning initially appeared to be the obvious path, the impressive performance of the off-the-shelf model, combined with our specific business needs and constraints, prompted us to reconsider our approach. This experience underscores the importance of thoroughly evaluating all options and remaining open to unexpected solutions in the rapidly evolving field of AI and machine learning.
Getting valid queries from an off the shelf LLM
While the off-the-shelf model (in this case, Claude’s Sonnet 3.5) delivered remarkably solid results, bringing Query Helper V2 to a level we felt confident presenting to customers still required a significant amount of effort.
To determine if we could produce correct answers to all our customers' questions, we began testing with actual inquiries previously directed to Query Helper V1. The chart below shows improvement as we increased the complexity of our retrieval, validation and retry strategy. SQL generation is shown as a baseline since SQL generation is a much more common task (eg easier) for LLMs.
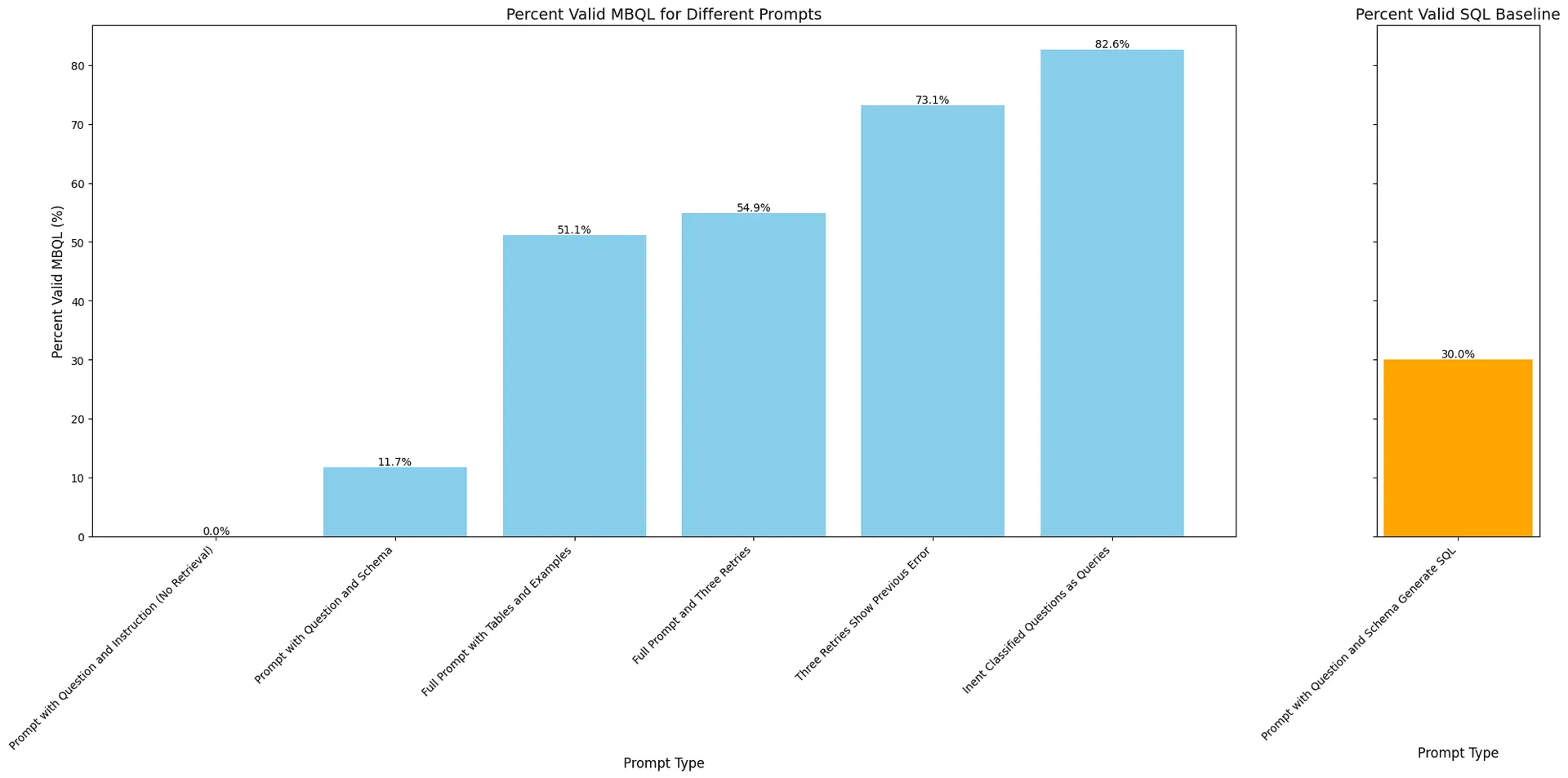
This chart shows the percentage of valid MBQL outputs for different prompt types. The chart to the right shows a baseline prompt with the Faros schema and SQL output for comparison.
Initially, we aimed to establish a baseline to assess how much our architecture improved upon the off-the-shelf LLM capabilities. When provided with no information about our schema, the models consistently failed to produce a valid query. This was expected, as our schema is unlikely to be part of their training data, and MBQL is a relatively niche domain-specific language.
Including our schema in the prompt slightly improved results, enabling the models to produce a valid query about 12% of the time. However, this was still far from satisfactory. We used the same prompt with SQL substituted for MBQL and found that an LLM would produce valid SQL about 30% of the time. This illustrates that SQL is easier for LLMs, but producing a schema specific query is a difficult task no matter what the query language.
Next, we provided examples and focused on relevant parts of the schema, which boosted our success rate to 51%. This approach required significant improvements to the information retrieved and included in the prompt.
Expanding our “golden” example dataset
Through careful analysis of user interactions, we discovered edge cases not covered by our initial example questions and instructions in Query Helper V1. To address this, we've been continuously updating our “golden” dataset with new examples. This involves adding examples for edge cases and creating new ones to align with changes in our schema. This ongoing refinement helps ensure that Query Helper can effectively handle a wide range of user inputs.
Bringing in examples from customer queries
Some customers have developed customized metric definitions which they use as the basis for all their analysis. We can't capture these definitions with our standard golden examples, as those examples are based on typical use of our tables. To address usage patterns specific to how different companies customize Faros AI, we needed to include that customization in the prompt without risking information leakage between customers. To achieve this, we utilized our LLM-enhanced search functionality (see diagram below for details) to find the most relevant examples to include in the prompt.
Customer specific table contents
To create the correct filters and answer certain questions, it’s necessary to know the contents of customer-specific tables, not just the column names. Therefore, we expanded the table schema information to display the top twenty most common values for categorical columns. We also limited the tables shown to the most relevant for answering the customer question.
Adding validation and retries
Including all this information gave us more accurate queries, substantially boosting success from the zero-shot schema prompt. However, 51% accuracy wasn't ideal, even for a challenging problem. To improve, we implemented a series of checks and validations:
- Fast assertion based validation of query format and schema references.
- Attempting to run the query to identify runtime errors.
- Recalling the model if an error occurred, and including the incorrect response and the error message in the prompt.
These steps boosted our success rate to 73%, which was a significant win. But what about the remaining 27%? First, we ensured our fallback behavior was robust. When the generated query fails to run after all 3 retries, we revert to a descriptive output, ensuring the tool performs no worse than our original setup, providing users with a starting point for manual iteration.
Finally, remember at the beginning of this blog post when we mentioned that customers asked all kinds of things from our original Query Helper? To thoroughly test our new Query Helper, we used all the questions customers had ever asked. By using our intent classifier to filter for questions answerable by a query, we found that our performance on this set of relevant questions was actually 83%. For inquiries that the intent classifier identified as unrelated to querying our data, we developed specialized knowledge base tools to address those questions. These tools provide in-depth information about data processing and creation, custom expression creation, and Faros AI documentation to support users effectively.
Putting the system into production
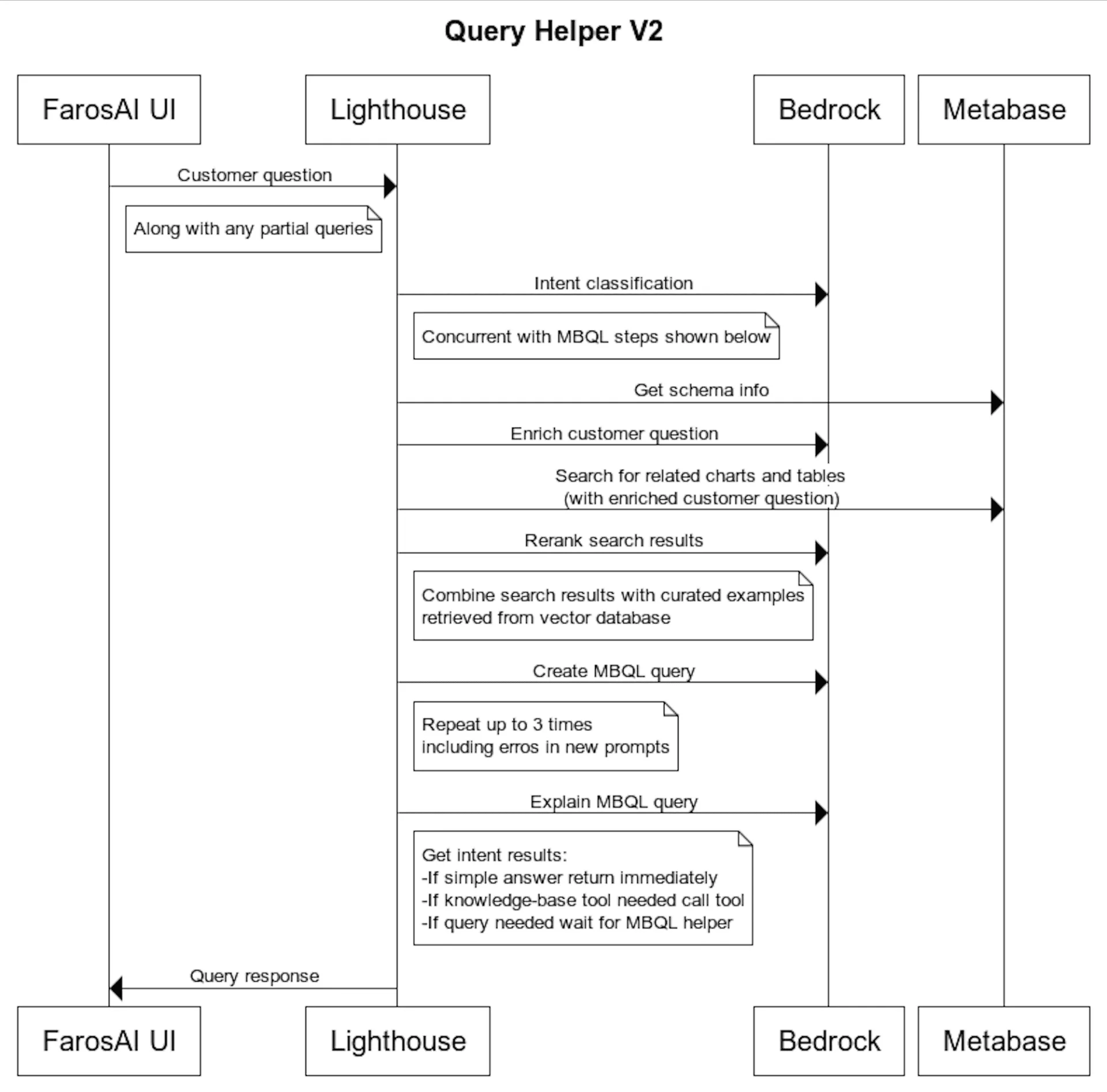
The final task was to ensure the process runs in a reasonable amount of time. Although LLMs have become much faster over the past year, handling 5-8 calls for the entire process, along with retrieving extensive information from our database, remains slow. We parallelized as many calls as possible and implemented rendering of partial results as they arrived. This made the process tolerable, albeit still slower than pre-LLM standards. You can see the final architecture below.
Was it worth it?
Providing our customers with the ability to automatically generate a query to answer their natural language questions, view an explanation, and quickly iterate without needing to consult the documentation is invaluable. We prioritize transparency in all our AI and ML efforts at Faros AI, and we believe this tool aligns with that commitment. LLMs can deliver answers far more quickly than a human, and starting with an editable chart is immeasurably easier than starting from scratch.
While we're optimistic about the potential of fine-tuned models to enhance speed and accuracy, we decided to prioritize delivering V2 to our users swiftly. This strategy allowed us to launch a highly functional product without the complexity of deploying a new language model. However, we're closely monitoring usage metrics. If we observe a significant increase in V2 adoption, we may consider implementing a fine-tuned model in the future. For now, we're confident that V2 offers substantial improvements in functionality and ease of use, making a real difference in the day-to-day operations of engineering managers worldwide.
Now, when our customers need insights into the current velocity of a specific team or are curious about the distribution between bug fixes and new feature development they can easily ask Query Helper, review the query used to answer it, and visualize the results in an accessible chart. They can even have an LLM summarize that chart for them to get the highlights.

Leah McGuire
Leah McGuire has spent the last two decades working on information representation, processing, and modeling. She started her career as a computational neuroscientist studying sensory integration and then transitioned into data science and engineering. Leah worked on developing AutoML for Salesforce Einstein and contributed to open-sourcing some of the foundational pieces of the Einstein modeling products. Throughout her career, she has focused on making it easier to learn from datasets that are expensive to generate and collect. This focus has influenced her work across many fields, including professional networking, sales and service, biotech, and engineering observability. At Faros, she develops the platform’s native AI capabilities.
Read the report to uncover what’s holding teams back—and how to fix it fast.

What to measure and why it matters.
And the 5 critical practices that turn data into impact.


- Engineering throughput is up
- Bugs, incidents, and rework are rising faster
- Two years of data from 22,000 developers across 4,000 teams

Tokenmaxxing: Why AI token consumption isn't engineering productivity
Tokenmaxxing—treating AI token consumption as a productivity metric—is repeating the lines-of-code mistake. Data from 22,000 developers points to a better way to measure AI engineering impact.

